Architecture
Overview
 {#rsb-architecture}
{#rsb-architecture}
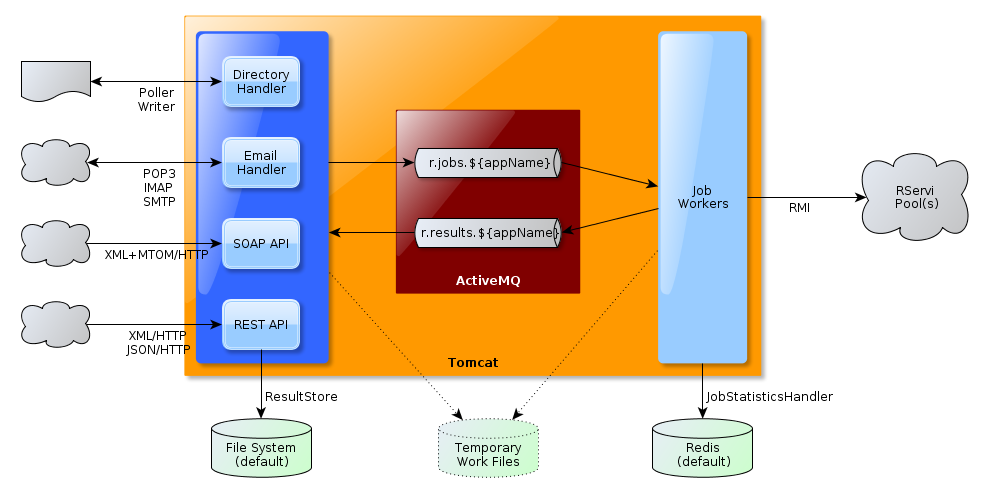
The architecture of RSB is organized around a messaging core that handles job requests and results.
The goal of this messaging core is twofold:
- it throttles the workload towards pool(s) of remotely managed R nodes, which are the ones in charge of actually processing the jobs,
- it stores the results until they get propagated to their relevant destination (application specific result files for the REST API, immediate response for the SOAP API, emails or response directories).
The messaging core consists in an embedded JMS provider (ActiveMQ) which hosts queues that are specific to the applications submitting R jobs. This allows a segregation of the submitted jobs and their related results. It also opens the door for creating application specific job workers in order to boost the priority of job execution (discussed further on).
The job workers can optionally report statistics on a pluggable store, like Redis.
Job Acceptors and Result Handlers
Specific job acceptors and result handlers are deployed as frontal elements to the messaging core described previously. They handle the specifics of the particular protocol, format or transport they deal and take care of communicating with the job queues and reading responses from the response queues.
Here is a summary of the different job acceptors and their mechanics:
- REST: handles raw (API style) and multi-part (web form style) HTTP requests. It works in an asynchronous manner: jobs are submitted and acknowledged with a unique ID, which is used to later on retrieve the corresponding result. Worker responses are dequeued from the response queues and immediately written to a result store, from where they're served over HTTP. The REST API offers functions for browsing and deleting these result files.
- SOAP: MTOM-enabled web service that offers synchronous semantics over the shared messaging core, this by consuming the result queue in a blocking manner on behalf of the client performing the SOAP call.
- POP3/IMAP & SMTP: works asynchronously, regularly polling an inbox for jobs and routing responses over SMTP
- Directory Deposit: works asynchronously too, scanning a deposit directory and writing results back into another directory. Processed jobs are archived in a third directory.
Though they present very different semantics, all the above acceptors use the same messaging core, which allows a complete decoupling of the job accepting phase from the job processing one.
Jobs and results are transported as serialized objects over JMS and respectively extend AbstractJob and AbstractResult.
Job Workers
Job Types
RSB supports two main types of jobs:
- Multi-files jobs: usually composed of several data files and an R script.
- Function call jobs: a single String payload (XML or JSON) passed to a predefined R function.
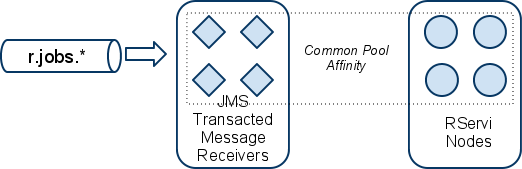
Default configuration: No Application Bias
 {#img-job_workers_default}
{#img-job_workers_default}
By default, a single pool of JMS transacted message receivers consume all the R jobs in all the r.jobs.* queues. This JMS pool is sized to match the number of nodes in the targeted RPooli pool. That way, each concurrent worker thread that will fetch a job and request an R node to process it will never starve.
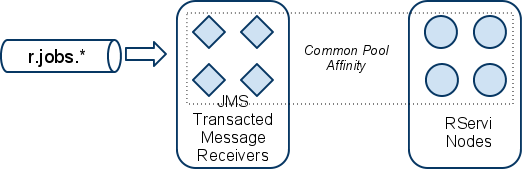
Optional configuration: Application Dedicated Pools
 {#img-job_workers_app_bias}
{#img-job_workers_app_bias}
If an application needs to have its jobs processed with a higher precedence than the other applications, the idea is to create a dedicated pool of transacted JMS message receivers sized accordingly with the other dedicated pools, the common pool and the actual number of available nodes on RPooli.
A JMS filter is used on the common pool of receivers so they do not consume jobs of the privileged application. Conversely, the consumers of the privileged application work only with the specific jobs queue of the privileged application.
Optional configuration: Application Dedicated RPooli Instance
By default, RSB connects to a single RPooli instance and uses the nodes it finds there for its R processing needs.
It is also possible to configure RSB to use application specific RPooli instances. This allows to guarantee that the execution of certain jobs only occur on a server where R is configured with the desired extensions or where the desired operating system is in use.
Job Error Handling
RPooli Node Starvation
If the processing of a particular R job fails because no RPooli node was available, processing will be retried again. This happens by letting the exception received from RPooli client (because of the unavailability of node) roll-back the transaction into which the JMS message has been consumed. The JMS provider will then redeliver the message, after a configured amount of time and for a configured number of attempts.
If the maximum number of retry attempts is reached, the failing job will be sent to a dead letter queue consumed by an RSB service which takes care of reporting the error to the original application (via the relevant results queue) and to the RSB admin.
Faulty Job
If a job is not processable because it contains error (wrong XML, bad R syntax…) it will not be retried. It is immediately rejected and reported faulty to the calling application through the relevant results queue.